

最近在使用openwebui的时候,一直在考虑接入tts,让ai开口说话。但是由于无论是openai方案(硅基流动)还是微软方案,都有一个很大的弊端——没法自定义声线!只能用寥寥几个声音,让人完全没有交流兴趣!
网上开源的tts项目很多,那么……岂不是只要改写一下api接口,就可以伪装成openai,接入openwebui呢?思路有了,开始整活儿!!
我使用的是github上开源的项目vits-simple-api,本身就已经是非常傻瓜式配置,有超超超多可用的声线模型,完美适配需求。
首先我们先来研究一下vits-simple-api原本的接口文档。
1、vits原接口文档
根据vits-simple-api的readme文档,可以看到:
它适配的请求格式为:
http://127.0.0.1:23456/voice/vits?id=15&streaming=true&text=你好&api_key=$API_API_KEY
是一个GET请求,其中id为选择的声线模型的id,streaming为是否流式响应的开关,text为需要的文本,api_key为验证密钥(在config.yaml中设置)
而通过查询openai的接口文档可以看到,其支持的请求格式为:
curl https://你的api服务器地址/v1/audio/speech \
-H "Authorization: Bearer $API_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "tts-1",
"input": "你好,世界!",
"voice": "alloy"
}' \
--output speech.mp3是一个POST请求格式。
2、适配openwebui接口
方案一:中转程序
最最简单的方式,当然是套一层中转,把前端(openwebui)发送的openai样式的POST请求,通过中转程序转换为后端vits-simple-api可以识别的GET请求,然后再把通过vits处理后的二进制音频流原封不动发送到前端,就可以完美实现openwebui接入vits了。这样做的好处当然是不用调整vits-simple-api的代码,几乎不需要相关技术,只需要打开vits,再打开中转程序,将中转程序的地址填入openwebui即可。这样做的弊端就是,需要同时开启两个程序,前台会比较乱。
以下代码仅做演示和方法验证只用,非常不建议生成环境使用:
from flask import Flask, request, jsonify, Response
import requests
import os
app = Flask(__name__)
# 后端服务地址
BACKEND_URL = "http://127.0.0.1:23456/voice/vits"
@app.route('/v1/audio/speech', methods=['POST'])
def proxy_audio_request():
try:
# 从请求头中获取API密钥
auth_header = request.headers.get('Authorization', '')
if not auth_header.startswith('Bearer '):
return jsonify({"error": "Invalid Authorization header format"}), 400
api_key = auth_header.split('Bearer ')[1].strip()
# 解析请求体
data = request.get_json()
if not data:
return jsonify({"error": "Invalid request body"}), 400
# 提取必要参数
input_text = data.get('input', '')
voice_id = data.get('voice', '')
if not input_text or not voice_id:
return jsonify({"error": "Missing required parameters (input or voice)"}), 400
# 构建后端请求URL
params = {
'id': voice_id,
'streaming': 'true',
'text': input_text,
'api_key': api_key
}
# 转发请求到后端
backend_response = requests.get(
BACKEND_URL,
params=params,
stream=True # 流式处理响应
)
# 检查后端响应状态
if backend_response.status_code != 200:
return jsonify({
"error": f"Backend service returned error: {backend_response.status_code}",
"details": backend_response.text
}), backend_response.status_code
# 定义响应生成器,将后端响应流式返回给前端
def generate():
for chunk in backend_response.iter_content(chunk_size=1024):
if chunk:
yield chunk
# 返回响应,保持与后端相同的Content-Type
return Response(
generate(),
content_type=backend_response.headers.get('Content-Type', 'audio/mpeg'),
status=backend_response.status_code
)
except Exception as e:
return jsonify({"error": f"Server error: {str(e)}"}), 500
if __name__ == '__main__':
# 可以通过环境变量配置服务端口,默认使用5000
port = int(os.environ.get('PORT', 5000))
# 生产环境中应将debug设置为False,并使用合适的WSGI服务器
app.run(host='0.0.0.0', port=port, debug=True)方案二:修改vits程序访问路由
本方案由于需要修改vits程序代码,有一定危险性,建议修改前做好文件备份。
通过阅读代码,发现访问路由主要由两个文件控制,一个是app.py,也就是主程序文件;一个是tts_app/voice_api/views.py。
要在views.py中添加响应路由和逻辑,并在app.py中更新CORS配置以支持新的/v1/audio/speech端点。
在tts_app/voice_api/views.py文件的末尾添加以下代码:
@voice_api.route('/v1/audio/speech', methods=["POST"])
def v1_audio_speech():
try:
# 获取请求数据(JSON格式)
request_data = request.get_json()
# 解析新格式的参数
model = get_param(request_data, "model", "", str) # 模型参数暂不使用
text = get_param(request_data, "input", "", str) # 对应原text参数
voice_id = get_param(request_data, "voice", config.vits_config.id, int) # 对应原id参数
# 保留原有VITS接口的默认参数
format = config.vits_config.format
lang = config.vits_config.lang.lower()
length = config.vits_config.length
noise = config.vits_config.noise
noisew = config.vits_config.noisew
segment_size = config.vits_config.segment_size
use_streaming = config.vits_config.use_streaming
except Exception as e:
logger.error(f"[V1_AUDIO_SPEECH] {e}")
return make_response("parameter error", 400)
logger.info(
f"[V1_AUDIO_SPEECH] model:{model} voice:{voice_id} format:{format} lang:{lang} "
f"length:{length} noise:{noise} noisew:{noisew} segment_size:{segment_size}"
)
logger.info(f"[V1_AUDIO_SPEECH] len:{len(text)} text:{text}")
# 参数验证
if check_is_none(text):
logger.info(f"[V1_AUDIO_SPEECH] text is empty")
return make_response(jsonify({"status": "error", "message": "text is empty"}), 400)
if check_is_none(voice_id):
logger.info(f"[V1_AUDIO_SPEECH] speaker id is empty")
return make_response(jsonify({"status": "error", "message": "speaker id is empty"}), 400)
if voice_id < 0 or voice_id >= model_manager.vits_speakers_count:
logger.info(f"[V1_AUDIO_SPEECH] speaker id {voice_id} does not exist")
return make_response(jsonify({"status": "error", "message": f"id {voice_id} does not exist"}), 400)
# 语言校验
speaker_lang = model_manager.voice_speakers[ModelType.VITS][voice_id].get('lang')
lang_list, status, msg = get_lang_list(lang, speaker_lang)
if status == "error":
return make_response(jsonify({"status": status, "message": msg}), 400)
# 语言自动检测配置
if (lang_detect := config.language_identification.language_automatic_detect) and isinstance(lang_detect, list):
speaker_lang = lang_detect
# 流式传输只支持MP3格式
if use_streaming and format.upper() != "MP3":
format = "mp3"
logger.warning("Streaming response only supports MP3 format.")
# 生成音频文件名
fname = f"{str(uuid.uuid1())}.{format}"
file_type = f"audio/{format}"
# 构建请求状态
state = {
"text": text,
"id": voice_id,
"format": format,
"length": length,
"noise": noise,
"noisew": noisew,
"segment_size": segment_size,
"lang": lang_list,
"speaker_lang": speaker_lang,
}
# 处理流式请求
if use_streaming:
audio = tts_manager.stream_vits_infer(state)
response = make_response(audio)
response.headers['Content-Disposition'] = f'attachment; filename={fname}'
response.headers['Content-Type'] = file_type
return response
# 处理非流式请求
else:
t1 = time.time()
audio = tts_manager.vits_infer(state)
t2 = time.time()
logger.info(f"[V1_AUDIO_SPEECH] finish in {(t2 - t1):.2f}s")
# 缓存音频(如果配置开启)
if config.system.cache_audio:
logger.debug(f"[V1_AUDIO_SPEECH] {fname}")
path = os.path.join(config.system.cache_path, fname)
save_audio(audio.getvalue(), path)
return send_file(path_or_file=audio, mimetype=file_type, download_name=fname)修改app.py中的CORS配置:
CORS(app, resources={
r"/voice/*": {"origins": config.http_service.origins},
r"/v1/audio/speech": {"origins": config.http_service.origins}
})然后再重启程序,就可以直接接入openwebui了。
3、openwebui设置
打开你的openwebui管理员界面,语音设置:
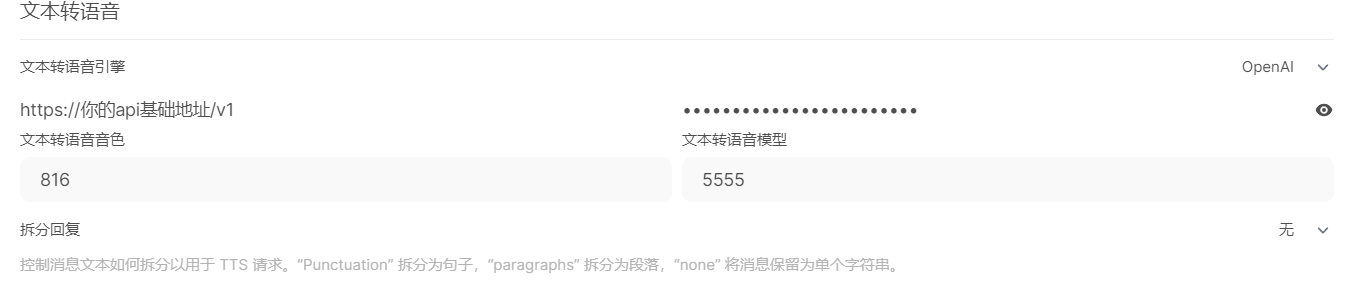
填入你的vits地址后边加上/v1,在密钥位置,需要填入vits的config文件中配置的api_key。文本转语音模型位置随便填写任意字符都可以,文本转语音音色位置,需要填写模型的id,可以浏览器访问你的vits地址,来找到对应的模型id。
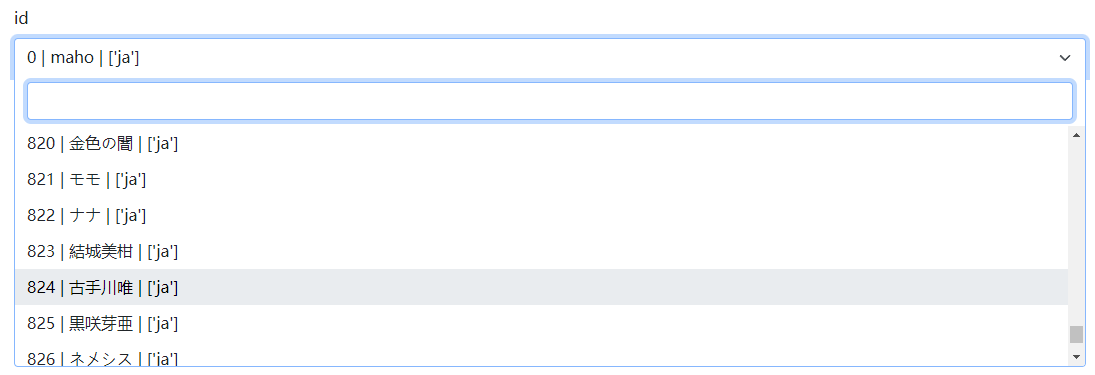
不出意外的话,就可以顺利地把openwebui接入vits了,让你更沉浸地和AI沟通!